
【导读】AI芯片领域又有大爆料!近日,知乎突然出现了一个劲爆提问 “如何看待寒武纪新一代人工智能芯片(疑似思元/MLU270)规格?”,提问者以匿名方式贴出了疑似寒武纪下一代云端AI芯片MLU270的相关信息,包括芯片外观以及某些具体参数。

知乎用户曝光的寒武纪下一代云端AI芯片——思元270(MLU270)
根据问题和回答记录中显示,似乎已有多家厂商接触到了相关资料,经他人在网上披露信息后,寒武纪下一代芯片规格被提前曝光。
在智能芯片领域,寒武纪被称为这一行业的先行者,“先行者”的行踪被泄露,自然会吸引众多从业者的关注与讨论——“新一代的云端AI芯片规格到底如何?”。该提问在短时间内就受到了知乎网友的广泛关注,阅读次数迅速过万。
独家爆料:“思元”年初悄然注册,数据遭泄,性能或超越NVIDIA最新一代芯片
据泄露照片显示,寒武纪的新一代云端AI芯片MLU270已于今年年初研制成功,主要包括如下五点特性:
a.基于台积电16nm工艺打造。
b.架构代号从上一代的MLUv01升级到了MLUv02。
c.内建视频解码单元(似乎是专门为视频处理市场配置)。
d.但按照寒武纪一直把MLU系列芯片定位为通用智能芯片来看,MLU270应该能够继续支持语音和自然语言处理等重要AI任务。
e.峰值方面,这颗芯片提供int4 256Tops, int8 128Tops的惊人性能,功耗为75w,与全球AI芯片龙头NVIDIA的最新一代Tesla T4基本持平。
在围绕新品的讨论中,这款新品是否与国际业内巨头NVIDIA持平也是知乎网友热议的一点。

大多数网友的看法都是持积极态度。虽然NVIDIA在国际范围内颇有“一家独大”的态势,但卓越的学术成就以及融资优势仍让很多网友看好寒武纪:对于前途大好的AI芯片市场,玩家越多,越有意思——“有新的竞争者加入进来对业内每一家都是好事”。
但也有网友认为超越NVIDIA绝非易事,峰值高低并不能直接决定市场上的胜负,如何接近核心客户可能是寒武纪需要跨过的更高门槛,也是能否与NVIDIA等巨头一决胜负的关键。另外,业内反馈Tesla T4在75w功耗条件下实测性能距离理论峰值有较大差距,不知寒武纪能否突破这一瓶颈,未来尚需相关用户公布实测结果。

寒武纪思元270芯片内部分技术参数
值得注意的是,照片中出现的”思元”这个名字,很可能是寒武纪云端芯片品牌MLU(Machine learning unit)的中文名。笔者顺藤摸瓜,查了一下国家商标局的网站( http://sbj.saic.gov.cn/sbcx/),发现寒武纪已经在年初注册了“思元”商标。
国家商标局网站,寒武纪注册“思元”信息
有网友在网站回答题主时反馈,“MLU”这个名词有些拗口,平时和同事交流时容易和“MCU”混淆。新的“思元”品牌,貌似可以解决这个小问题,也有利于打开市场知名度。

知乎匿名用户评论
来自同行的疑惑:“思元270”专注AI推断任务还是兼做训练任务?
耐人寻味的另一点是,照片中只包括了整数性能的数据,也没有交代是这颗芯片是专注人工智能的推断任务还是兼做训练任务,令一些同行感到疑惑。
查阅寒武纪以往公开信息,发现寒武纪不存在任何一款代号是MLU270的芯片产品。寒武纪的上一代产品MLU100已经公布,是专注于推理的AI芯片,而且发布时间尚不满一年,不太可能是同一产品线自相残杀式的迭代,更有可能是专注于训练的新产品。

寒武纪上一代芯片——MLU100
照片中仅公布了低精度整数性能,存在两种可能性:
一是表格中有意遗漏了浮点数据;
二是寒武纪在低精度训练领域实现了关键性突破。
而新智元从业内传闻看更倾向于第二种可能性。
实际上,低精度训练的需求在业界由来已久。算法工程师使用GPU做训练,通常使用其浮点运算单元,主要是因为在有监督学习的BP算法中,只有精确的浮点运算才能记录训练时很小的增量。而浮点运算单元占用的芯片面积和功耗相比于整数运算器都要大很多倍,导致单位芯片面积的处理能力要差很多。
目前业界在人工智能的推断类应用上,发现整数运算可以不影响模型的精度,因此用于推断的芯片已经大量集成了整数运算器或低精度浮点运算器。但业界一直在尝试是否有机会用代价更低的整数运算器实现更为复杂的训练功能,这样可以在不增加芯片面积和功耗的前提下,大幅提升芯片做训练的运算能力。但这个问题在业界也还没有普适的解决方案。
如果寒武纪真的在低精度训练领域实现了突破,那将会是AI芯片领域的重大消息。新智元在发稿前尝试联系寒武纪确认该技术信息,但目前尚未有回复。

思元270系列板卡实物照片
据了解,寒武纪在过去三年一直保持每年一代的产品迭代速度。在终端领域:
2016年推出寒武纪1A处理器IP;
2017年推出双核的寒武纪1H;
2018年推出寒武纪1M。
迄今已经服务于数千万台终端设备。
寒武纪CEO陈天石曾表示,寒武纪的云端智能芯片产品,迭代速度会和终端产品一样快。从这一次的消息泄露来看也确实如此,从去年初的MLU100到今年的MLU270。能够以一年一代的速度进行研发的,国内也仅有华为海思一家在消费类手机芯片能做到。
在发稿前,新智元专门回顾了寒武纪去年发布会的新闻,发现陈天石博士在去年曾提到一款名为“MLU200”的云端芯片。这次泄露的MLU270芯片已经研制成功,但是否就是去年发布会时陈天石提到的MLU200,抑或是寒武纪还另有名为MLU200的产品?
无论如何,大型AI芯片能在一年时间迭代一代确实令人意外,但如果寒武纪能够同时研发多款高复杂度的芯片,这可能意味着寒武纪已经具备非常完备的芯片研发能力,在迈向AI芯片新巨头的道路上又前进了一步。
我们今天如何造芯?回望寒武纪三年AI修行之路
那么,寒武纪在智能芯片这条路上到底是如何发展的呢?新智元对此做了一下梳理:
2016年发布的寒武纪1A处理器(Cambricon-1A),是世界首款商用深度学习专用处理器。
2017年8月,寒武纪科技一亿美元的A轮融资消息传出,在A轮融资后估值达到10亿美元,成为全球AI芯片领域第一个独角兽初创公司。

2016年发布的寒武纪1A处理器(Cambricon-1A)
2017年11月,寒武纪召开自成立以来的首场发布会,公布了系列新品及公司未来路线图——“3年内占领10亿智能AI终端,占领中国云端高性能芯片1/3市场份额”。发布会上,寒武纪三款全新的智能处理器IP产品亮相:面向低功耗场景视觉应用的寒武纪1H8、拥有更广泛通用性和更高性能的寒武纪1H16,以及面向智能驾驶领域的寒武纪1M。

2017年11月寒武纪首场发布会
2018年5月,寒武纪发布第三代IP产品Cambricon 1M,以及最新一代云端AI芯片MLU100和板卡产品。其中,MLU100采用寒武纪最新的MLUv01架构和TSMC 16nm的先进工艺,可工作在平衡模式(1GHz主频)和高性能模式(1.3GHz主频)下,平衡模式下的等效理论峰值速度达每秒128万亿次定点运算,高性能模式下的等效理论峰值速度更可达每秒166.4万亿次定点运算,但典型板级功耗仅为80瓦,峰值功耗不超过110瓦。

2018年5月发布的寒武纪MLU100
2018年6月,寒武纪宣布完成数亿美元的B轮融资,投后整体估值达25亿美元,继续领跑全球智能芯片创业公司。
智东西第一时间向寒武纪一位主要负责人求证了曝光的思元MLU270芯片信息,对方表示,这(MLU270芯片相关信息被曝光)是一次意外,相关图片可能是从合作伙伴处流出,不过寒武纪确实已经注册了“思元”这个商标,该款芯片的正式发布还未敲定。届时智东西将进行进一步报道。另据一位安防行业主要厂商的高层透露,寒武纪芯片(应指该新款)在安防领域的应用,将要落地,正在评估。
延续寒武纪云端芯片MLU(Machine Learning Unit)系列,其二代云端AI芯片代号为“MLU270”。如今距离其在第一代云端推理AI芯片MLU100的推出刚满1年。
另外在今年初,寒武纪已为旗下芯片注册两大中文商标名,分别是“思元”、“玄思”。现在云端芯片基本可以确定中文名是“思元”了,说不定“玄思”会是给终端系列产品取得名字。
昨日,某一匿名用户又补上了一张更加直观的产品规格照片。根据泄露的照片显示,寒武纪新一代AI芯片名为MLU270,中文名为思元270,于2019年年初研制成功,主要规格参数如下:
工艺:TSMC 16nm
峰值性能:256 TOPS [int4],128 TOPS [int8],64 TOPS [int16]
系统接口:x 16 PCIe Gen3
形状因素:Low-Profile PCIe
散热设计功耗(TDP):75W
从曝光参数可见,寒武纪在制程上的打法相对稳健,延续上一代选用台积电16nm工艺,并没有像美国的赛灵思、AMD、Wave Computing等企业的新一代云端AI芯片那样采用7nm工艺。
在芯片架构上,新一代芯片从上一代MLUv01架构升级为MLUv02架构。
另外,思元270中内建视频解码单元,应该是为海量的视频处理市场而专门配置。
从性能方面来看,思元270似有向NVIDIA Tesla T4看齐的趋势。两者对比如下:
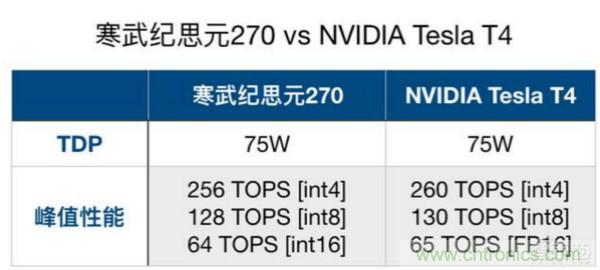
根据图表,思元270的功耗为75W,与Tesla T4刚发布时的功耗持平,不过现在NVIDIA的官网显示Tesla T4的功耗已经低至70W。
在峰值性能方面,思元270显示的数据非常接近Tesla T4。
有知乎匿名用户称,Tesla T4的实测性能表现并不如预期,而且溢价较高,认为新的竞争者加入是好事。另有用户称,业内传闻说,寒武纪新一代芯片可以同时做训练和推理。还有一位自称来自海康研究院员工匿名表示,其院长也比较喜欢这款芯片产品。
或在低精度训练领域实现关键性突破
随着深度学习的快速发展,数据科学工作者发现如果芯片能使用低精度计算的方法获得近似答案,其在速度和能耗比上将有很大优势,这对于移动设备及其他功率受限的设备相当适用。
虽然低精度计算听起来很好,但该方法目前主要应用于推理,而非训练。
这是因为,当使用较少的位进行训练时,舍弃的位会增加误差,致使训练的准确度被限制,通常训练至少需要FP32及更高精度的浮点运算。
尽管许多研究人员在探索使用低精度训练且不会限制准确度的算法,目前市场上尚未出现有效且普遍适用的相关应用。
根据思元270目前曝光的信息,不过只公布了低精度整数性能,并未公布浮点数据。部分业内人士猜测,或许寒武纪在低精度训练领域实现了关键性突破。
如果这一猜测成真,这意味着寒武纪将为现有云端AI训练芯片做出重要的贡献。
此前在媒体采访中,寒武纪执行董事罗韬曾经介绍,寒武纪设立了三条产品线:
1、智能终端处理器IP授权,可以集成到手机、安防、汽车、可穿戴等终端芯片中。
2、智能云服务器芯片,比如昨天发布的MLU100和即将发布的思元270,作为PCIE加速卡插在云服务器上。另外去年发布会上提到的支持训练和推理的MLU200云端芯片,不确定是否就是今日泄露的思元270芯片。
3、家用智能服务机器人芯片,这条产品线暂时没有产品发布,就寒武纪研发产品的高效性来看,该产品线也相当值得期待。
云端训练AI芯片战事将起,谁能挑战英伟达
按照寒武纪惯例,今年上半年应该会有一次发布会。在这次发布会上是否能够顺利地看到此次遭泄露的“思元270”,又是否真如曝光数据所示,峰值高达256Tops,亦或像网友猜测的那样,在低精度训练领域中实现了关键性突破?值得期待。
云端训练战场正在狼烟四起。过去几年,英伟达凭借GPU的超强算力以及cuDNN、TensorRT等一系列AI软件,在深度学习云端领域构建起强大而稳固的生态,尤其是在云端训练方面基本上一家独大、所向披靡。

而随着寒武纪等一批实力芯片玩家加入赛道,云端训练的板块未必会一如既往地稳定不变。对于AI芯片创企而言,建立强大的生态系统是长久发展的关键,这需要持续的研发投入、过硬的技术、围绕芯片衍生的全套软硬件开发维护。
假使寒武纪云端芯片的落地应用经过了时间和市场的检验,无论是在安防还是在其它领域,将成为这些领域取代英伟等进口芯片的选择,前景很大,这对亟待芯片国产化的我国产业而言无疑将是好消息。
推荐阅读:

