
【导读】韩国科学技术院研究团队近日开发了一种用于扬声器识别的基于机器学习的声学传感器,该声学传感器使用机器学习算法可以实现97.5%的扬声器识别率,比参考麦克风降低75%的错误率。
声学传感器作为人类和机器之间最直观的两方通信设备之一而受到关注。然而,传统的声学传感器使用电容器型装置来测量两个导电层之间的电容,导致灵敏度低,识别距离短以及扬声器识别率低。
该小组通过模仿人类耳蜗中的基底膜,制造了一种柔性压电薄膜。谐振频率振动梯形压电薄膜的相应区域,该区域通过高度灵敏的自供电声学传感器将声音转换为电信号。
这种可以从更远距离探测到微小声音的多声道压电声学传感器的灵敏度是传统声学传感器的两倍多,它可以提供更多的语音信息。
此外,该声学传感器使用机器学习算法可以实现97.5%的扬声器识别率,比参考麦克风降低75%的错误率。
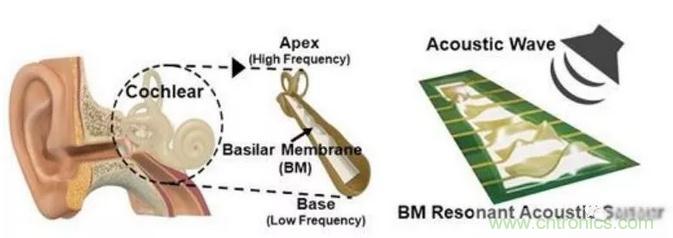
一种模拟人工耳蜗的柔性压电声学传感器
人工智能扬声器识别是未来个性化定制服务的下一个重点。然而,传统技术试图通过使用软件升级来提高识别率,导致扬声器识别率受限。该团队用创新的柔性压电声学传感器取代了现有的硬件进而改进了扬声器识别系统。
压电声传感器的进一步软件改进,将大大提高不同环境下的扬声器和语音识别率。Lee教授说:“用于扬声器识别的高灵敏度的自供电声学传感器可用于个性化语音服务,如智能家用电器、人工智能秘书、全天候物联网、生物认证和金融科技。”
注:该论文发表在《Nano Energy》其题目为《基底膜启发式自供电声传感器》和《用于语音识别的基于机器学习的声学传感器》。

